前言
在 asp.net 上跑 jieba 做中文斷詞
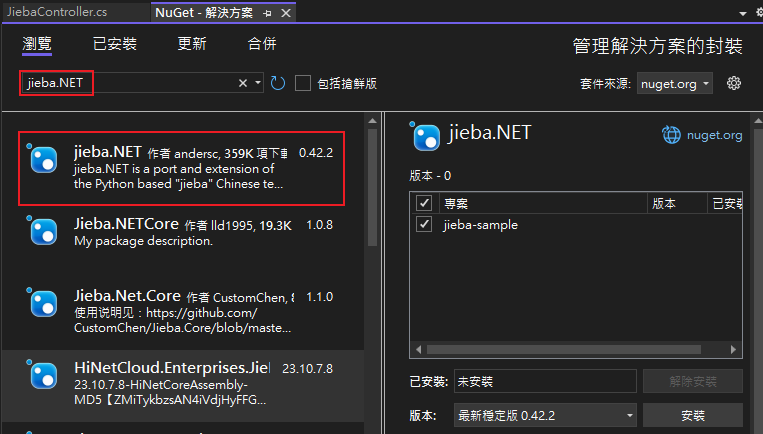
先安裝套件
- 查詢 jieba.NET
簡易 sample code
- 呼叫 chatgpt 生成簡易程式碼
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16using JiebaNet.Segmenter;
// 初始化 Jieba
var segmenter = new JiebaSegmenter();
// 分詞範例
string sentence = "我愛自然語言處理";
// 默認為精確模式
var segments = segmenter.Cut(sentence);
Console.WriteLine("【精確模式】:{0}", string.Join("/ ", segments));
// 全模式
segments = segmenter.Cut(sentence, cutAll: true);
Console.WriteLine("【全模式】:{0}", string.Join("/ ", segments));
// 搜尋引擎模式
segments = segmenter.CutForSearch(sentence);
Console.WriteLine("【搜尋引擎模式】:{0}", string.Join("/ ", segments)); - 快樂得執行看看
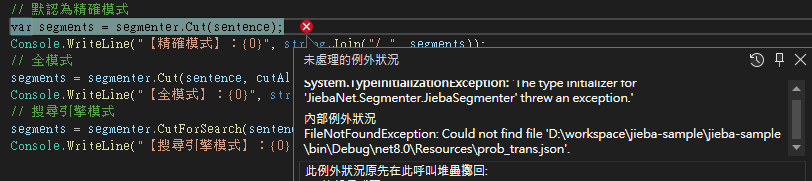
出現錯誤1
DirectoryNotFoundException: Could not find a part of the path 'D:\workspace\jieba-sample\jieba-sample\bin\Debug\net8.0\Resources\prob_trans.json'.

- 看來C#的套件沒有包含必要檔案
- 只好去 jieba.NET github 去下載,把 Resources 資料夾丟進去專案裡,預設路徑是 Resources
執行成功
- 可以看到結果長這樣
1
2
3【精確模式】:我/ 愛自然/ 語言/ 處理
【全模式】:我/ 愛/ 自/ 然/ 語/ 言/ 處/ 理
【搜尋引擎模式】:我/ 愛自然/ 語言/ 處理 - 但總覺得斷字的效果很差啊
- 李組長眉頭一皺發現事情並不單純
- 原來字典檔根本沒有用到
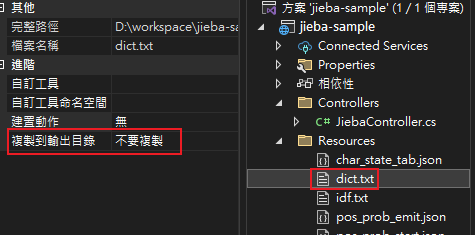
- 點一下 dict.txt 在屬性中把「複製到輸出目錄」改成「有更新時才複製」
- 重跑一次
1
2
3【精確模式】:我/ 愛/ 自然/ 語言/ 處理
【全模式】:我/ 愛/ 自然/ 語/ 言/ 處/ 理
【搜尋引擎模式】:我/ 愛/ 自然/ 語言/ 處理 - 結果看起來正常多了
繁中字典
- 官方有提供支援繁中的字典 dict.txt.big
- 加上指定字典
1
2var segmenter = new JiebaSegmenter();
segmenter.LoadUserDict("D:\\workspace\\jieba-sample\\jieba-sample\\Resources\\dict.txt.big"); - 結果有把「自然語言」切出來了,更加準確
1
2
3【精確模式】:我/ 愛/ 自然語言/ 處理
【全模式】:我/ 愛/ 自然/ 自然語言/ 語言/ 處理
【搜尋引擎模式】:我/ 愛/ 自然/ 語言/ 自然語言/ 處理
自訂字典
- 把文字改成「我愛祈菈貝希毛絲」這樣有專有名詞的情況
- 會發現全模式會把貝希毛絲都切開來
1
2
3【精確模式】:我/ 愛/ 祈菈/ 貝希毛絲
【全模式】:我/ 愛/ 祈菈/ 貝/ 希/ 毛/ 絲
【搜尋引擎模式】:我/ 愛/ 祈菈/ 貝希毛絲 - 在字典中加上 「貝希毛絲 76 n」,再執行一次
1
2
3【精確模式】:我/ 愛/ 祈菈/ 貝希毛絲
【全模式】:我/ 愛/ 祈菈/ 貝希毛絲
【搜尋引擎模式】:我/ 愛/ 祈菈/ 貝希毛絲 - 這樣專有名詞也會正常被當作一個單詞處理